, image #4 - WeSoftYou")
This blog post dives into the concept of reinforcement learning from human feedback (RLHF), an approach that combines AI and machine learning with human wisdom. By leveraging reinforcement learning algorithms, this technique can tap into a powerful combination of computational power and insight provided by humans to enhance existing Artificial Intelligence systems.
RLHF could transform how we think about AI operations research in general – get ready for a thrilling journey!
The Power of Human Feedback in Reinforcement Learning
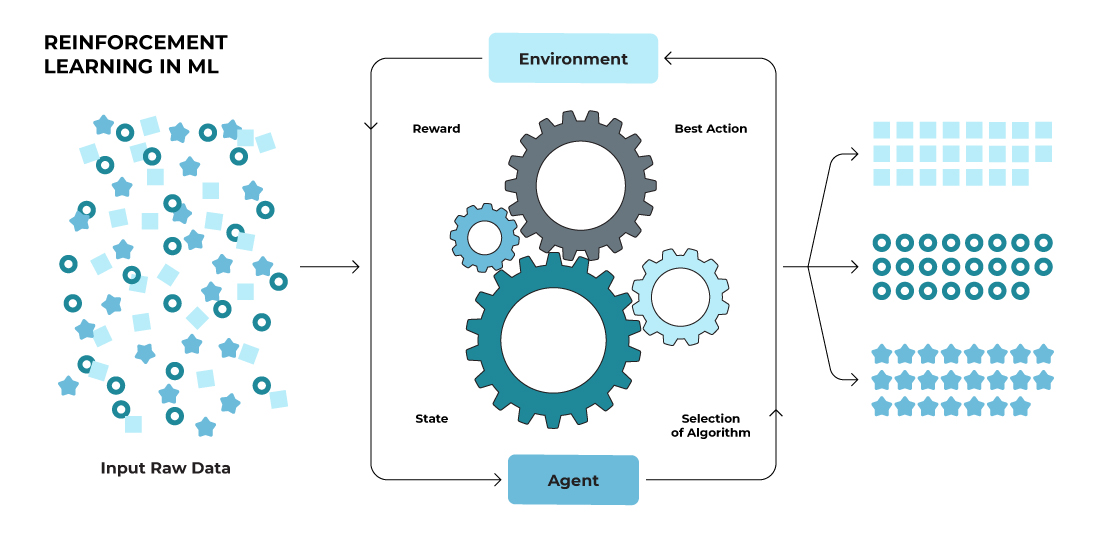
Reinforcement learning (RL) is an area of machine learning that allows agents to learn through their interactions with the world. By using a crafted reward system, it can be tricky to have enough detail included for complex tasks. Incorporating human feedback gives these systems more power in that they are now able to gain knowledge from people’s preferences and make better decisions faster. Through utilizing this powerful tool along with reinforcement learning algorithms, one has a much greater chance at obtaining improved intuitive decision-making results while also reducing any unforeseen time needed as well as errors made during training processes.
Role of Human Feedback
In the domain of AI, human feedback can help a neural network or learning agent progress in complex and ambiguous situations. By providing useful guidance to reinforce their behavior policy, agents are able to surpass autonomous learning limitations as well as facilitate complicated neural networks designs.
There are several ways for interpreting these reinforcement signals. From encoding raw data into its internal system representation or teaching language model to how humans express advice messages. In language models training this is especially relevant because understanding accurate tones when speaking is crucial for success here too.
Benefits of Human Feedback
Using human feedback in reinforcement learning can help boost accuracy, scalability and efficiency. Reward shaping is one way of taking advantage of this technique. By providing intermediary rewards, the agent will be able to learn faster and more precisely, especially when dealing with large language models. Evaluative feedback could then translate into numerical values for a deferred and reward model, which links back MDPs (Markov Decision Processes) rewards with value functions via RL algorithms, ultimately maximizing the potential benefits offered by human input for better knowledge gathering during reinforced learning processes.
Key Concepts in Reinforcement Learning from Human Feedback

The power of human feedback in reinforcement learning can be better understood when one understands its core components. This includes the agent, environment, state space, reward function, policy and people’s preferences and input. By having a grasp on these fundamentals it is much easier to understand how incorporating human comments can amplify the proficiency of AI agents – from guiding investigations up to refining policies thus creating smarter systems which abide by mankind’s expectations.
Agent, Environment, and State Space
Reinforcement learning is composed of three main components: a learning system (agent), the world in which it operates (environment) and all possible situations that may occur (state space). The agent takes actions based on its current state, obtaining feedback from the environment through rewards. The goal for this algorithm is to discover an optimal policy that maximizes cumulative reward over time. Meaning mapping states into actions able to generate optimal results. In some cases, the agents can be fully aware of their surroundings while partially observed scenarios also exist where only limited knowledge applies.
Reward Function and Policy
In reinforcement learning from human feedback, the reward function and policy are both fundamental factors in dictating how an agent interacts with its environment. The goal is to align the behavior of the agent with expectations and values generated by humans. Policy gradient methods like Proximal Policy Optimization (PPO) aid in this pursuit because they help balance exploration against exploitation while ensuring a successful policy can be learned that maximizes cumulative future rewards as outputted by a given reward function, which was also garnered from human preferences. With these techniques, it becomes possible for agents to learn directly through recognition of signals provided via interaction between man and machine.
Human Preferences and Feedback
In reinforcement learning from human feedback, inputting user preferences and responses into the training and learning process helps to shape an agent’s behavior towards attaining desired outcomes. Using a preference comparison algorithm incorporates this type of information in order for agents to understand more complex problems and customize their strategies based on people’s values. Through using cross-entropy loss, AI systems can be trained with regards to predicting humans’ judgments between two paths through reward functions determined by such feedback. Overall these methods make it easier for machines powered by human guidance to acquire knowledge faster, leading to efficient and better performance that aligns with what we want as users.
Deep Reinforcement Learning with Human Feedback
Deep reinforcement learning combined with human input is an ever-evolving area, harnessing the capabilities of deep learning and also making use of what people can provide. Thanks to proximal policy optimization (PPO), this combination has been used in a variety of cases such as natural language processing (NLP) and robots.
In order to deepen our understanding of combining reinforcement learning with human feedback, we will delve into PPO’s applications within NLP and robotics, while highlighting any hurdles faced when using it for those purposes. It could open up opportunities for improvements on existing practices within the field moving forward too!
Proximal Policy Optimization (PPO)
OpenAI’s Proximal Policy Optimization (PPO) algorithm, released in 2017, is an optimization strategy utilized for policy optimization within the reinforcement learning framework with human feedback. PPO uses a combination of a value network and trust region optimizer to provide many advantages such as greater sample efficiency and stronger tolerance when it comes to hyperparameter tuning than other reinforcement learning methods.
Using this technique can be quite challenging due to its instability which may arise during complex tasks like natural language processing or robotics. Not only that, but maintaining and updating the said algorithm could also become tricky requiring careful tuning along the way.
Applications in Natural Language Processing (NLP) and Robotics
Deep reinforcement learning that incorporates human feedback has been applied to multiple disciplines such as Natural Language Processing (NLP) and robotics. With this technique, language models become more accurate when it comes to generating contextually suitable texts in tasks like text summarization or machine translation. On the other hand, complex robotic activities like object grasping and navigation of dynamic environments, can be improved by leveraging humans’ insights into these systems through using deep reinforcement learning with its corresponding feedback. This type of training helps robots refine their strategies, resulting in higher efficiency levels among them.
Implementing Reinforcement Learning from Human Feedback in Python
It’s time to dive deep into Python and unlock the power of reinforcement learning with human feedback! We’ve got you covered, step-by-step, from setting up a large language model in your environment so that it integrates successfully with human input all the way through to assessing how well your model performs.
By following our guide line by line, you can harness this powerful technique for use in any project of yours. Using reinforcement learning from human feedback will give a huge boost to whatever work you’re doing – let’s get started now!
Setting Up the Environment
To start learning from human feedback with reinforcement in Python, you will need to set up your environment. For this purpose, there are numerous libraries available like KerasRL, Pyqt Learning, Tensorforce, RL_Coach and TFAgents. These tools offer a lot of useful materials for developing the ideal setting for your project related to reinforcement learning technology.
One such popular library is OpenAI’s Gym, which includes existing ecosystems as well as enables customized universes through its gym-builder option. To get started with installing Gym, all it takes is working on a pip package manager followed by a few lines of code, making sure that after these steps taken correctly you can establish an operational atmosphere suitable for reinforcement learning!
Integrating Human Feedback
Once you have your environment set up, the next step is to incorporate human feedback into your reinforcement learning model. Using algorithms like Proximal Policy Optimization (PPO) in Python can help achieve this goal and strengthen an agent’s performance by taking on our preferences and values. Other methods such as Policy Shaping or Bayesian Q-learning may be employed for guiding the AI towards a desired result too. Combining humans’ insight with machine intelligence can create more powerful models that are better tuned to what we want from them.
Evaluating Model Performance
After applying a reinforcement learning algorithm based on human feedback in Python, it is necessary to assess the efficacy of your model and confirm that its operation meets expectations. Utilizing accuracy, precision, recall and F1 score can provide insight into how well your algorithm works and where potential improvements should be made.
Viewing a learning curve which visualizes performance levels over time as more data accumulates offers additional information about when the best results have been reached or if the best results have been achieved. Training from human feedback would bring any meaningful gain.
Challenges and Limitations of Reinforcement Learning from Human Feedback
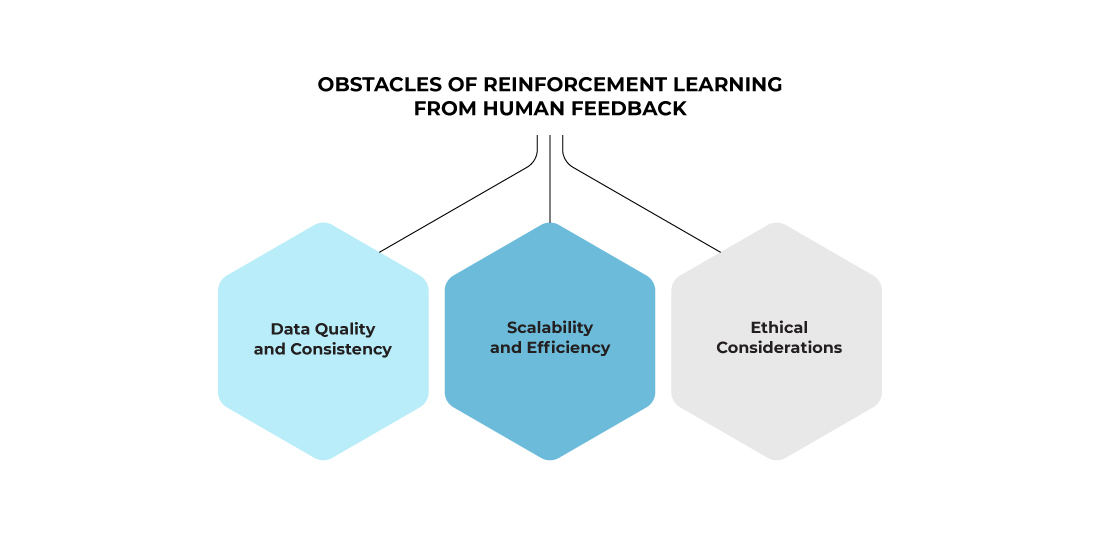
The use of reinforcement learning from human feedback presents its own set of challenges. Data quality and consistency, scalability and efficiency as well as ethical considerations are the most pressing ones that need to be addressed in order for robust systems which benefit from user input can be developed. By understanding these issues more clearly, we would have a better chance at improving our AI technology with beneficial insights provided by people giving their thoughts on it through comments or ratings. Such an undertaking necessitates skillful management since any misstep could lead to negative consequences. Taking steps toward establishing feasible solutions has proven worthwhile in terms of fostering efficient reinforcement learning utilizing meaningful contributions given by humans regarding this matter.
Data Quality and Consistency
In order to ensure effective reinforcement learning from human feedback, it is necessary to address the challenges of data quality and consistency. Techniques such as data cleaning, validation and augmentation are key for ensuring accuracy in model training. Data cleaning consists of removing any irrelevant or inaccurate information from the dataset, while validation ensures that all information used by models is complete and accurate. Augmenting datasets with additional knowledge. Improves their capacity for making reliable predictions when trained using reinforcement learning methods based on human input. Proper attention must be given in order to eliminate sources of potential inaccuracy within a system which relies heavily upon receiving well-curated inputs through means related to humans providing instruction either directly or indirectly into machines so they can learn better over time.
Scalability and Efficiency
The main problem in reinforcement learning from human feedback is ensuring scalability and efficiency, as obtaining such responses may take too much time. To address this issue, automated systems, data sources or active learning techniques can be utilized to bolster the speed of training a model while adhering closer to individual preferences. This will ultimately help generate better results more quickly and accurately with regards to personal opinion on the topic than previously possible through manual input alone.
Ethical Considerations
When using human feedback in reinforcement learning, the ethical considerations of our actions are paramount. From privacy to consent and representation concerns, as well as potential social effects, all must be taken into account when constructing these AI systems for optimal performance while also maintaining ethics.
By considering such factors carefully, we can make sure that future AI models abide by appropriate standards with respect to values and expectations set forth by humans. Thus leading to a better use of reinforcement learning technologies, which will benefit society at large.
Benefits of RLHF
Enhanced Training Efficiency
- RLHF significantly enhances training efficiency by reducing the number of interactions an AI agent needs with its environment. This means faster learning and reduced computational resources required for reinforcement learning.
Safer Learning Environments
- RLHF allows AI agents to learn in safer environments. Instead of directly interacting with the real world, which can be costly or risky, agents learn from human feedback, minimizing the potential for accidents or costly mistakes during training.
User-Centric Customization
- RLHF facilitates user-centric customization of AI agents. By fine-tuning an agent based on human feedback, it can be tailored to specific user needs and preferences, making it more adaptable and relevant.
Addressing Exploration Challenges
- Traditional reinforcement learning often faces challenges in exploration, where agents must explore uncharted territory to learn effectively. RLHF provides a more guided approach, enabling agents to explore with a better understanding of desired behaviors.
Accelerated Learning Curve
- RLHF shortens the learning curve for AI agents. Instead of learning from scratch, they can leverage human expertise to quickly acquire useful knowledge and behaviors, reducing the time needed to become proficient.
Improved Policy Robustness
- RLHF helps in improving policy robustness. Agents trained with human feedback are more likely to exhibit consistent and reliable behaviors across different scenarios, reducing unexpected or undesirable outcomes.
Future Directions in Reinforcement Learning from Human Feedback
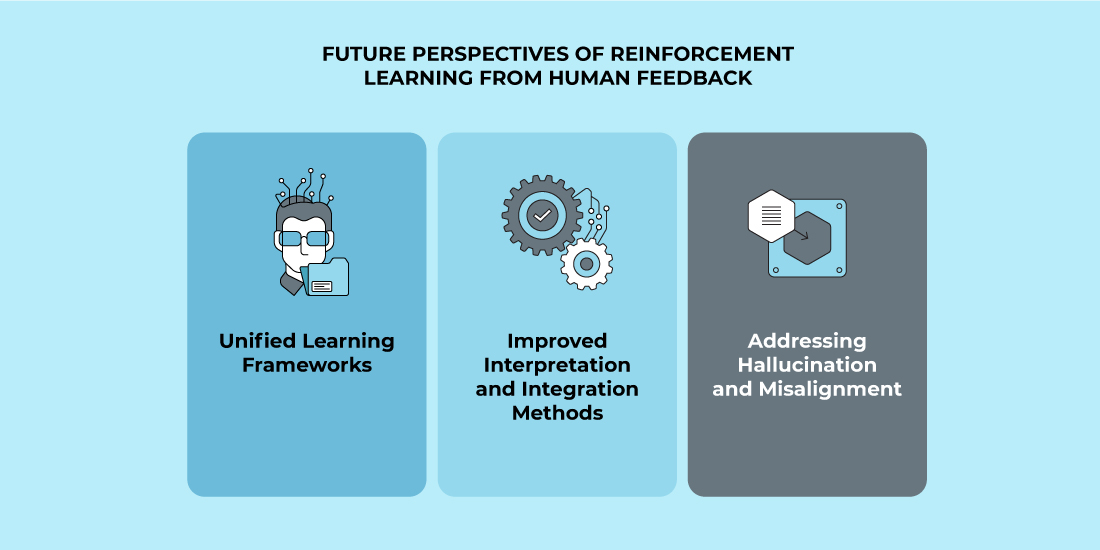
As we persistently strive to explore the potentials of reinforcement learning through human feedback, there are a number of promising avenues for reinforcement learning. Development. These include unified learning frameworks that will combine all our knowledge in this area, methods which improve and assimilate our interpretation processes. As well as how to confront hallucinations or misalignments encountered during experiments.
Through investigating such possibilities ahead and refining on what has already been established about reinforcement learning from humans’ input, it can open up opportunities where AI systems become increasingly refined yet tailored with humanity’s presence in mind.
Unified Learning Frameworks
Unified learning frameworks present an exciting opportunity to advance the application of reinforcement learning from human feedback. By providing a single API for various reinforcement learning approaches, such as value-based, policy-based and model-based methods, these platforms provide researchers and developers with one platform on which different techniques can be examined and compared easily. With unified structures in place, efficient systems that leverage human input are now more achievable than ever before – paving the way for faster advances in reinform cent learning benefiting from human feedback.
Improved Interpretation and Integration Methods
The advancement of reinforcement learning through human feedback is dependent on the ability to interpret and incorporate such guidance into its process. Natural language processing (NLP) and deep learning, for instance, can assist in determining finer points from this type of input, which would render more effective AI agents that reflect our ideals. By refining ways to draw out information while assimilating it with machine-learning approaches, one could greatly expand upon existing programs’ proficiency across many areas based on said feedback taken from humans themselves.
Addressing Hallucination and Misalignment
When it comes to reinforcement learning from human feedback, two major issues are at play: hallucination and misalignment. Hallucinating is when the agent creates inaccurate outputs due to an overgeneralization of inputted information. Meanwhile, with misalignment, the learner simply makes guesses rather than actually achieving what was meant as intended behavior. In order for more reliable systems that use reinforcement learning effectively to be created from humans’ input, these challenges must both be addressed head on through techniques such as reward shaping or engineering, this helps in making sure that the desired result is accurately attained. By doing so we can build AI applications which have improved accuracy coupled with a better understanding of how humans interact and behave, allowing us much greater insight into our own actions.
Summary
In summary, learning from human feedback utilizing reinforcement learning algorithms is a powerful tool that leverages the advantages of AI computation and insight provided by humans. By gaining an understanding of this field’s fundamentals, challenges, and possible directions in its evolution, we can create more effective systems while keeping them true to their original design intentions, given by humans.
As technological advances give us access to a bigger world where AI powered machines understand people better through reinforced human feedback. Let’s explore it together with a spirit open to fresh ideas so as to find solutions which are rooted in shared values amongst man & machine alike!
FAQ
Reinforcement Learning from Human Feedback (RLHF) combines traditional reinforcement learning with human input, enhancing machine learning by leveraging valuable human guidance, feedback, or demonstrations. It bridges the gap between human expertise and AI systems, improving learning and decision-making in complex environments.
In their 2017 paper, “Deep Reinforcement Learning from Human Preferences,” OpenAI offered an innovative concept: training deep reinforcement learning systems utilizing human feedback. This novel way of training language models and harnessing the power of reinforcement learning has enabled us to successfully carry out tasks such as document summarization and InstructGPT with greater ease than ever before.
Reinforcement learning in humans is evident when employing reward and punishment strategies. Positive actions can be reinforced with rewards, while undesired behavior should be countered through punishments to shape behavior over time. Providing feedback on progress. Guides the reinforcement of learned behaviors.
In reinforcement learning, feedback can come in the form of both positive and negative influences. Positive reinforcement encourages a certain response while on the other hand, negative discouragement acts to impede any undesirable behavior from occurring. For this reason, it is critical for the learning system to be able to differentiate which action produces desirable results versus those that don’t so as not to have its progress impeded by ineffective responses.


















